
W ubiegłotygodniowym zestawieniu pojawiły się podstawowe czynniki rankingowe Google. Dziś bliżej przyjrzymy się czynnikom jakościowym treści, które mają swoje potwierdzenie w istniejących patentach Google. W oparciu o tekst Bila Slavskiego Google Ranking Signals możemy dowiedzieć się znacznie więcej o wyszukiwarce Google i stosowanych w niej mechanizmach wyszukiwania.
Czas oglądania dla strony
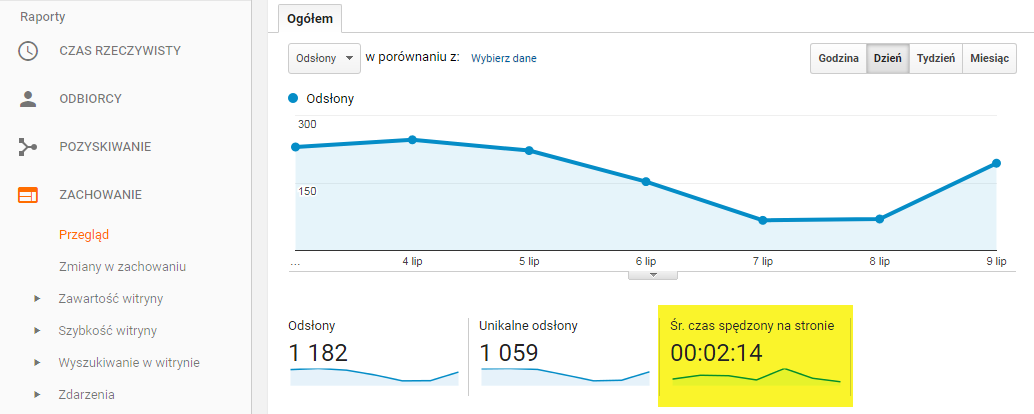
Google wie dokładnie na jak długo użytkownik zatrzymuje się, aby oglądać daną stronę, odbierając dłuższy pobyt na niej jako wartość treści strony WWW. Adekwatnie – krótki pobyt na witrynie oznacza, że użytkownik odbiera treści jako nieodpowiednie dla zadanego zapytania, co obniża pozycję tego wyniku w rankingu Google. Dla treści w formie filmów możemy to ocenić po średnim czasie oglądania – jeśli jest krótszy niż połowa całej długości filmu to oznacza, że użytkownicy szybko porzucają jego oglądanie, czyli nie jest on dla nich interesujący. Link do patentu Google: Ranking w oparciu o czas oglądania.
Zalecenia: Aby utrzymać uwagę użytkownika na stronie WWW warto zadbać o jakość treści na stronie głównej – nie może być nudna, ani banalna, a jednocześnie powinna być atrakcyjnie oprawiona wizualnie. Grafiki przedstawiające informacje, budzące emocje zdjęcia oraz krótkie filmy zatrzymują użytkownika na stronie na dłużej. Wpływ narzędzi utrzymujących uwagę odbiorców możemy badać w Google Analytics – zakładka „Przegląd”, parametr „Średni czas spędzony na stronie”.
Rozpoznawanie frazy kontekstowej
Frazy kontekstowe w rozmowach jest uwarunkowane przebiegiem rozmowy i zasobem wiedzy rozmówców. W języku pisanym my – jak i Google – posiłkujemy się słowami występującymi w otoczeniu frazy, której znaczenia szukamy. Inaczej zinterpretujemy słowo „aparat” w dwóch różnych clickbaitowych nagłówkach stron WWW: „Znana portrecistka straciła w ten sposób aparat podczas podróży!” oraz „Krzywe zęby? Założenie aparatu u dentysty nigdy nie było tak tanie!”. Frazy kontekstowe – w tym przypadku „portret”, „podróż”, „zęby”, „dentysta” – wskazują jednoznacznie wyszukiwarce, że szukane frazy to „aparat fotograficzny” oraz „aparat ortodontyczny”. Google korzysta z bazy wiedzy o słowach, które mają więcej niż jedno znaczenie i stosuje ją wyświetlając takie, a nie inne wyniki wyszukiwania. Link do patentu Google: Wyszukiwanie w oparciu o kontekst użytkownika.
Zalecenia: Wskazane jest nasycenie strony WWW frazami kontekstowymi, które jasno zdefiniują branżę i tematykę strony. Bil Slavski posługuje się przykładem słowa „jaguar”, które pojawi się na stronach WWW dotyczących: zwierząt, drużyny futbolu amerykańskiego czy programu Apple. W języku polskim, dobrym przykładem jest golf, który może mieć kontekst sportowy, odzieżowy czy motoryzacyjny. Zapewnienie fraz kontekstowych – czyli słów jak „dziergany”, „wełna”, „na długi rękaw”, „odzież” na stornie rozwiązuje problem wyświetlania się w wynikach wyszukiwania strony firmy sprzedającej golfy wełniane, kiedy użytkownik szuka miejsca do pogrania w golfa.
Modele językowe korzystające z algorytmów n-gram
N-gram to algorytm językowy, który, na podstawie posiadanej bazy tekstów w danym języku, jest w stanie przewidzieć kolejną sekwencję/słowo. Wykorzystuje się go między innymi do rozpoznawania mowy. Im większa ilość tekstów w bazie, tym większa celność przewidywań systemu n-gram.
Google wykorzystuje n-gramy do oceny jakości modelu językowego. Upraszczając – im wyżej Google oceni jakość językową treści na stronie WWW, tym mocniej wpłynie to na dobrą pozycję tej strony w rankingu Google. Biorąc pod uwagę fakt, że w bazie tekstów Google posiada historyczne zasoby literatury, możemy mieć pewność, że kryterium jakości treści wykorzystywanych do oceny zawartości strony postawione jest bardzo wysoko. Link do patentu Google: Przewidywanie jakości strony WWW.
Zalecenia: Pisanie treści na strony WWW powinno być wynikiem przemyślanej komunikacji, która zostanie uformowana w merytoryczny, spójny i językowo poprawny tekst. Będzie to wymagało nakładu pracy oraz bezwzględnego stosowania korekty przed publikacją, ale zaowocuje to wysoką jakością strony. Uważajmy na powtórzenia, nienaturalne konstrukcje, odmianę gramatyczną i styl.
Śmieciowy content treści
Google’owi zależy na wartościowych wynikach wyszukiwania dla swoich użytkowników – dlatego też stale udoskonala odfiltrowanie treści o znikomej wartości – po angielsku Gibberish Content (ang. gibberish – jazgot). Patent potwierdza, że Google jest w stanie rozpoznać, czy tekst był stworzony poprzez:
- Zautomatyzowane generatory tekstu,
- Skopiowanie z innego źródła, a następnie modyfikację przez przypadkowe zmiany pojedynczych słów,
- Translację z języka obcego.
Dodatkowo, Google posiada ogromną bazę wiedzy o stosowaniu języka (poprzez analizę m.in. zasobów literatury) i jego naturalnej stylistyce. Odbieganie od naturalnej gramatyki w połączeniu z brakiem fraz kontekstowych omawianych wyżej, daje Google’owi prawo twierdzić, że strona WWW jest tylko reklamą lub przekierowaniem, dlatego obniży on jej ranking. Tematyką tą zajmuje się nie tylko Google – pisaliśmy ostatnio o pozagooglowym narzędziu o wykrywania fałszywych recenzji na Google Maps Stopcraponthemap.com. Ponieważ usuwanie śmieciowych treści jest korzystne dla wszystkich użytkowników Internetu. Link do patentu Google: Wykrywanie śmieciowego contentu w zasobach.
Zalecenia: Jak w punkcie poprzednim – content musi być dopracowany pod względem jakościowym. Treści tworzone nie powinny być kopiowane, ani bezrefleksyjnie wklejane z translatora, bo jak wiemy – ten potrafi się mylić.
Wiarygodne wyniki wyszukiwania
Źródło wiarygodnej informacji wbrew pozorom nie jest oczywistą cechą strony WWW. Wiemy, że w oczach Google’a wiarygodne są strony rządowe (przykład autorytarnej cechy to domena gov.pl) albo strony Wikipedii, mimo że te nie zawsze są rzetelnym źródłem wiedzy.
Strony WWW zawierające pętlę przekierowań, błędy w kodowaniu, czy treści nieadekwatne do nagłówków podstron lub niepoprawnie używające fraz kluczowych, fraz kontekstowych i fraz pokrewnych, będą oceniane jako mało wiarygodne. Wiarygodność strony to nie tylko jej wysoka jakość.
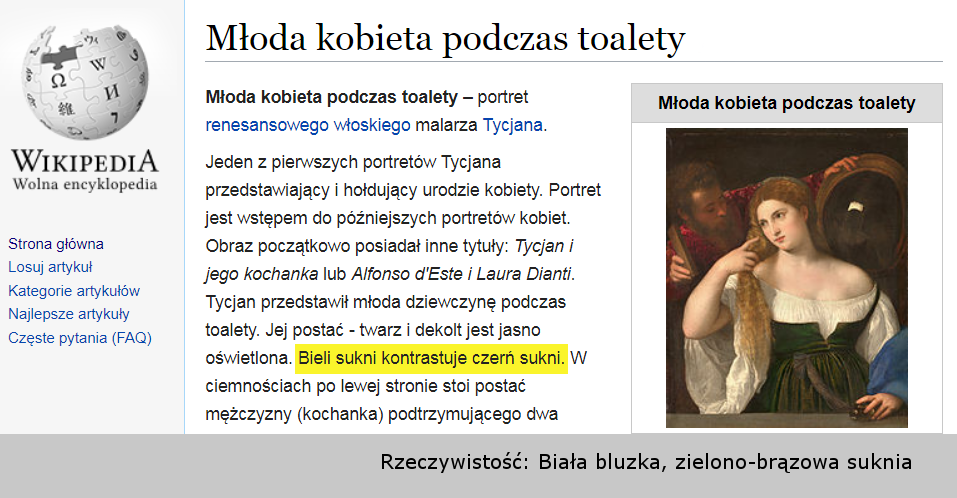
Przykładem może być podstrona witryny zawierająca Wzór Wniosku X – w tytule podstrony, w nagłówku i w pierwszym akapicie strony znajdziemy informację „Wzór Wniosku X”, a w treści strony załączony będzie plik PDF o tytule „Wniosek X – Wzór”. Osoba szukająca tego wniosku po wejściu na podstronę, pobierze PDF i zakończy poszukiwania – w oczach Google’a wyszukiwanie zostało zakończone interakcją satysfakcjonującą użytkownika. Patent mówi o wybraniu – spośród wyników wyszukiwania treści o dobrej jakości – tych stron, które są wiarygodne – a więc udzielają rzetelnych i konkretnych informacji. Link do patentu Google: Uzyskiwanie wiarygodnych wyników wyszukiwania.
Zalecenia: Dla Google’a liczą się trzy aspekty rzetelności: ekspertyza, autorytarność, wiarygodność (ang. Expertise/Authoritativeness/Trustworthiness w skrócie E-A-T). Więcej o E-A-T można poczytać tutaj w punkcie 5.3 oraz 6.1 między innymi o tym, że znaczenie mają: systemy zabezpieczeń płatności na stronie, wyczerpujące informacje o właścicielu strony i administratorze przetwarzania danych osobowych, satysfakcjonująca ilość wysokiej jakości treści bieżących oraz spełnianie wymogów E-A-T. Właściciele stron mają wiele do zrobienia w tym zakresie, ale uzyskana w oczach Google’a renoma portalu jest nie do przecenienia.
Budowanie wiarygodności strony WWW można podzielić na dwie części. Pierwsza dotyczy bardziej samej treści na stronie i budowania zagadnień związanych naokoło topical authority, czyli wyczerpywania contentem na stornie wszystkich zagadnień powiązanych. Warto w tej części zwrócić uwagę na: występowanie słów zależnych – przykładowo w narzędziu Senuto, podpowiedzi innych wyszukiwań dla danych słów, czy frazy o podobnej ilości wyszukiwań dla danej frazy na podstawie Keyword Plannera od Google’a. Żeby pokazać Google’owi, że jesteśmy specjalistą w danej dziedzinie, staramy się doszczętnie wyczerpać wszystkie zapytania. Druga część to budowane autorytetu SEO – tę część możemy w skrócie ująć jako budowanie wartościowego linkowania w oparciu o wysokiej jakości portale, czyli te, które mają widoczność organiczną, rozbudowany profil linkowy. Dobrze wypromowane serwisy będą się przekładać dla nas na jakość w oczach Google’a, tak jak pozostałe wskaźniki aktywności w usługach Google’owych, na przykład Gogole Maps. Łukasz Kacprzak, Specjalista SEO w CS Group Polska
Google i jego patenty rozwijają się stale w celu dostarczenia możliwie najtrafniejszych odpowiedzi w możliwie najkrótszym czasie. Dziś omawiane czynniki rankingowe Google skupiają się mocno na jakości treści i użytkowniku. Czy użytkownik szukając odpowiedzi sprawdza autorytet witryny, jej model językowy czy też opuszcza strony ze śmieciowym contentem? Przyglądając się patentom Google’a można dojść do wniosku, że Google bardziej niż sami użytkownicy dba o wiarygodność podanych im informacji w wynikach wyszukiwania.

Przeczytaj również:
 Czynniki rankingowe Google, część 1. Linkowanie, fraza kluczowa i szybkość strony
Czynniki rankingowe Google, część 1. Linkowanie, fraza kluczowa i szybkość strony- Optymalizacja SEO. Czym jest? Co się na nią składa?
- Jak stworzyć stronę internetową dla branży motoryzacyjnej?
- Jak dopasować działania Digital Marketingowe do firmy? Poradnik dla początkujących
- Jak bardzo słowa kluczowe będą ważne dla SEO w 2022 roku?

















{kind=link}